行ベースの処理に限定したかいもなく、バグバグなCSVパーサを作ってしまいました。
今回はテストケースの作成と構造的なバグへの対応についてです。
- プラットフォームについて
- 処理の概要
- テストケースの検討
- テストのポイント
- 閑話休題 〜 テストケースを設計するために必要なこと
- JUnitを使ってテストケースを生成する
- 前回作成したコードのバグについて
- とりあえず、まとめ
プラットフォームについて
今回は NetBeans 6.9.1(Linux版)でJavaのバージョンをJava 5に設定してコードを書いていて、バージョン管理はSubversionで行なっています。
ユニットテストの実施は JUnit 4.xで行なっています。
OSは関係ないと思いますが、Ubuntu 10.04 LTSを使っています。
処理の概要
この部分は後から書いているのですが、文書で書くと何をいっているのかサッパリなので図を載せることにしました。
今回作成したパーサは改行で分割した文字列をカンマでさらに分割しています。
いくつかのパターンは次のようになります。
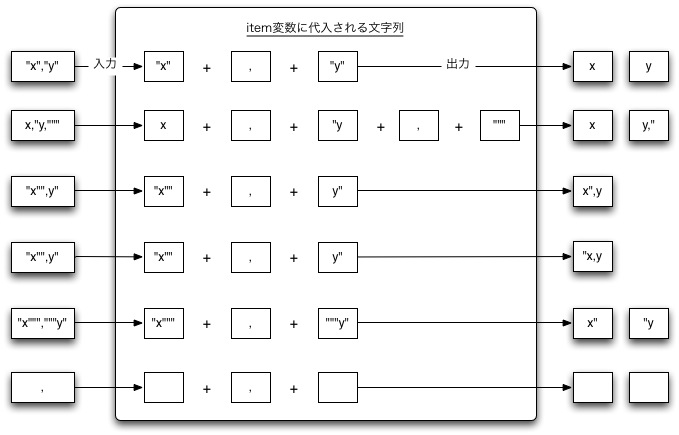
テストケースの検討
テストは総当たりで入力を与えて正しく出力するかを確認することにします。
今回のアプリケーションは規模は小さいですが、設計時点では状態遷移を定義していないので、内部処理は一つの巨大なメソッドで処理しており、内部構造のテストには向かないケースでしょう。
とりあえずjava.util.Scannerを使ってCSVファイルのパーサを作る事自体が目的なので、こういった背景は受け入れてテストケースを考えてみようと思います。
テストのポイント
処理をざっと眺めて内部状態が変化する値を中心に考えます。
今回の処理は区切り記号である ,(カンマ) と "(ダブルクォート) によって状態が変化します。 内部では isQuoteBlock 変数一つだけを準備していますが、処理の流れは1行全体が "x", (isQuoteBlockの値は変化しない)の場合と "x,", (isQuoteBlockの値によるループと分岐処理)では大きく違います。
そこでクォート文字列の中でカンマが表われ、その前後の文字列にダブルクォートが含まれる場合に処理が正しく行なえるかを中心に考えていきます。
いくつのフィールドを並べるか
処理単位について考えると、 ダブルクォートで囲まれた範囲 を識別するための処理が複雑になっています。
例えば1行が """x""",y から「"x"」を取り出す処理(一語として"""x"""を処理)は "x,",y から「x,」を取り出す処理("xと"に分けて処理)や """x""," から「"x",」を取り出す処理(カンマ直前の""を無視する)などとの違いを考える必要があります。
その反面 x,x といったダブルクォートで囲まれていないカンマで区切られた要素は、isQuoteBlock変数がfalseである限りは、あっさりと処理を終えています。
ダブルクォートで囲まれていない要素をいくつ並べても意味はなさそうです。
またダブルクォートが閉じられた時点で値は返されてループは終了するため、外部からは1フィールドを取り出した時点で内部状態を表わすisQuoteBlock変数がfalseになっている事が確認できれば、次のダブルクォートから始まる文字列は正しく処理されることがわかります。
そこで複数のフィールドを含むのでななく、1つのダブルクォート文字列を評価してその直後のisQuoteBlock変数がfalseになっている事を確認することにします。
クォート文字列は何文字で作るのか
まずクォートで囲まれた要素として「適当な文字('x')」、「カンマ(',')」、「ダブルクォート('""')」、「空文字('')」が重複して並ぶとします。
'x'と''のポジションを入れ替える必要はないので、'x'と'""'、2文字の各要素の間にカンマが入る5文字も並べば良さそうだと考えたのですが、余裕をみて6文字を並べることにしました。
閑話休題 〜 テストケースを設計するために必要なこと
今回のプランは内部構造を考慮しているためホワイトボックステストもどきですが、どちらかといえばエラーケースを考えない境界値テストに近いと思います。
そもそもの設計がフィーリングなので厳密なホワイトボックスを実施するにはプログラマ(自分ですけれども)を越える理解が必要になるでしょう。 そんなのは現実的じゃないんですけどね。
こういった事から分かることは、ちゃんとした設計、特に 内部処理のアルゴリズム設計 は、テストを実施するチームが他にある場合は重要です。
外部設計をちゃんとやったものの、顧客には良くみえない、内部設計、プログラミングを簡略化すると陥りがちなのかもしれません。
特にエラーケースをエラーとして処理しなければいけないビジネスアプリケーションほど、重要だと思うんですけどね。 そういうビジネスアプリは顧客にパワーがないと重視されずにテストの段階で不具合が発覚するのかもしれません。
JUnitを使ってテストケースを生成する
具体的処理
入力用CSVファイルと期待する処理結果を格納した外部ファイルをTestCaseクラスのコンストラクタで作成します。
- test/csv.autogen2/case1.csv - 入力に使うCSVファイル#01 (e.x. "x,""x,")
- test/csv.autogen2/case1.ans - case1.csvと同時に作成する正解ファイル#01 (e.x. x,"x,)
- ...
テストケースの作成
Netbeansで作成したテストケース
package org.yasundial.csvscanner.unittest;
import org.junit.After;
import org.junit.AfterClass;
import org.junit.Before;
import org.junit.BeforeClass;
import org.junit.Test;
import static org.junit.Assert.*;
import org.yasundial.csvscanner.CSVManager;
import org.yasundial.csvscanner.Row;
/**
* $Id: AutoGenedUnitTestBlog.java 29 2010-10-29 02:21:42Z yasu $
* @author Yasuhiro ABE <yasu@yasundial.org>
*/
public class AutoGenedUnitTestBlog {
/**
* A placeholder
*/
CSVManager manager;
/**
* A words list for generating unquoted string.
* <p>
* e.x.) """x"",y"
*/
String[] qwords = {"x", ",", "\"\"", ""};
/**
* A unquoted notation against each words words.
*/
java.util.HashMap<String, String> unquoted;
/**
* A directory path which places all csv files.
*/
String outputBasedir;
/**
* Prefix string for each csv file.
*/
String csvPrefix;
/**
* A internal counter object which is used as a sequence number of output filename.
*/
long loopCounter;
/**
* File Path Generator Utility Class
* <p>
* Its filename is generated based on given sequence number and prefix string.
* It is also used for generating answer file object.
* <p>
* e.x.) (sequence, suffix) == (12, ".csv"),
* then generated path will be "test/csv.autogen/case12.csv"
*/
private java.io.File getCSVFilepath(long sequence, String suffix) {
return new java.io.File(outputBasedir + java.io.File.separator
+ csvPrefix + sequence + suffix);
}
public AutoGenedUnitTestBlog() {
csvPrefix = "case";
manager = null;
// prepare the output directory
outputBasedir = "test" + java.io.File.separator + "csv.autogen2";
java.io.File tmpFileObj = new java.io.File(outputBasedir);
if (!tmpFileObj.exists()) {
tmpFileObj.mkdir();
}
unquoted = new java.util.HashMap<String, String>();
unquoted.put("x", "x");
unquoted.put(",", ",");
unquoted.put("\"\"", "\"");
unquoted.put("", "");
loopCounter = 0;
for (String i : qwords) {
for (String j : qwords) {
for (String k : qwords) {
for (String l : qwords) {
for (String m : qwords) {
for (String n : qwords) {
java.io.File csvFile;
java.io.File ansFile;
java.io.File ansFile1;
java.io.FileWriter writer = null;
try {
csvFile = this.getCSVFilepath(loopCounter, ".csv");
ansFile = this.getCSVFilepath(loopCounter, ".ans");
// prepare the csv file
writer = new java.io.FileWriter(csvFile);
String record = "\"" + i + j + k + l + m + n + "\"";
writer.write(record);
writer.close();
// prepare the answer file for first field
writer = new java.io.FileWriter(ansFile);
writer.write(unquoted.get(i) + unquoted.get(j) + unquoted.get(k)
+ unquoted.get(l) + unquoted.get(m) + unquoted.get(n));
writer.close();
} catch (java.io.FileNotFoundException e) {
} catch (java.io.IOException e) {
} finally {
try {
if (writer != null) {
writer.close();
writer = null;
}
} catch (java.io.IOException e) {
}
}
loopCounter++;
}
}
}
}
}
}
System.out.println("[info] loopCounter: "
+ loopCounter);
}
@BeforeClass
public static void setUpClass() throws Exception {
}
@AfterClass
public static void tearDownClass() throws Exception {
}
@Before
public void setUp() {
}
@After
public void tearDown() {
}
@Test
public void letsTest() {
// prepare the base dirctory
for (long i = 0; i
< loopCounter; i++) {
java.io.File csvFile = this.getCSVFilepath(i, ".csv");
assertTrue(csvFile.exists());
// load first answer file
java.io.File ansFile = this.getCSVFilepath(i, ".ans");
assertTrue(ansFile.exists());
java.io.BufferedReader reader = null;
try {
manager = new CSVManager(csvFile);
assertTrue(manager.hasNext());
Row row = manager.fetchRow();
assertTrue(row.hasNext());
// read first field.
String input = row.next();
assertFalse(row.hasNext());
reader = new java.io.BufferedReader(new java.io.FileReader(ansFile));
char[] readChars = new char[256];
int readCharsLen = reader.read(readChars);
reader.close();
// compare first field
String answer;
// if the readCharsLen is -1, then the new String() method will be failed.
if (readCharsLen == -1) {
answer = "";
} else {
answer = new String(readChars, 0, readCharsLen);
}
assertEquals("[check answer #" + i + "]", input, answer);
// check the post condition
assertFalse(manager.isQuoteBlock());
assertFalse(manager.hasNext());
} catch (java.io.FileNotFoundException e) {
assertTrue(false);
} catch (java.io.IOException e) {
assertTrue(false);
} finally {
if (manager != null) {
manager.close();
manager = null;
}
if (reader != null) {
try {
reader.close();
reader = null;
} catch (java.io.IOException e) {
}
}
}
assertTrue(true);
}
}
}前回作成したコードのバグについて
さて、テストケースを走らせると見事に完走しませんでした。
本質的に処理を間違えているところもあれば、条件式が意図した通りになっていないといった残念なバグがいろいろあります。
クォート文字列の終りを判断する正規表現の間違い
クォート文字列の終りを判断している個所は2個所あります。
まずはクォートで始まって、かつ終っている場合で、この場合はisQuoteBlock変数は変化しません。
修正後のコード1
} else if (item.startsWith(this.quoteString)) {
- if (item.endsWith(this.quoteString)) {
- // spacial case; the line is just a "a","b".
+ if (item.endsWith(this.quoteString)
+ && (item.matches(String.format("^%s(%s%s)*%s$", // item is "" or """".
+ this.quoteString, this.quoteString, this.quoteString, this.quoteString))
+ || item.matches(String.format("^%s.*[^%s]+(%s%s)*%s$", // item is "x", """x" or "x""".
+ this.quoteString, this.quoteString, this.quoteString, this.quoteString, this.quoteString)))) {
+ // spacial case; the item is begin/end with '"', such as "a", "b""", "" or """"次のケースは一旦isQuoteBlockがtrueになってから、クォート文字列の終りを判断している部分です。
ここは文字列の最後が奇数個のダブルクォートが連続しているかどうかで判断しています。
修正後のコード2
+ if (item.endsWith(this.quoteString)
+ && (item.matches(String.format("^%s(%s%s)*$", // item is " or """
+ this.quoteString, this.quoteString, this.quoteString))
+ || item.matches(String.format("^.*[^%s]%s(%s%s)*$", // item is x" or x"""
+ this.quoteString, this.quoteString, this.quoteString, this.quoteString)))) {
+ // case: item must be b", b""", or ".
正規表現の文字列が固定な場合は、java.util.regex.Patternオブジェクトをインスタンス変数にしておくべきなんでしょうが、それはしていません。
最終的な形に落ち着くまでに、何回か正規表現の指定方法をミスしてしまい、たびたび意図せずにこの条件式の中に飛び込んでいきました。
int型カウンタのオーバフロー
これは本体に処理ではなくJUnitのコードに関連した問題です。
ループを複数回ネストしているため、当初int型で宣言していたもっとも内側をカウントするloopCounter変数がオーバーフローしました。
6文字までは問題なかったのですが、ループのネストを増やしたところ問題が発生したのでlong型に直しています。
close()しないオブジェクト達
これもループの数が増えたところで発覚したメモリリーク系の問題です。
テストケースではCSVManagerオブジェクトを生成したままにしていて、CSVManagerオブジェクトが内部で保持しているscannerオブジェクトについては何もしていませんでした。
CSVManagerクラスにclose()メソッドを追加して、内部ではscannerオブジェクトのclose()メソッドを呼ぶような代理処理を行なっています。
追加個所 - CSVManager::close()
public void close() {
if (scanner != null) {
scanner.close();
scanner = null;
}
}内部状態のチェック
テストのためだけに内部状態が参照できるように変更を加えて、ユニットテストの中でダブルクォートの要素を読み取った後で値がfalseである事を確認しています。
追加個所 - CSVManager::isQuoteBlock
+ public boolean isQuoteBlock() {
+ return this.isQuoteBlock;
+ }その他、細々としたこと
他のクラスで区切り文字をハードコードしていた部分は、変更可能なように修正しています。
Patternオブジェクトをあらかじめ準備しておくとか、修正するべきところはありそうですが、そこはおいおいやっていくことにしようと思います。
とりあえず、まとめ
動くものはできましたと。
それが正しく動きそうだということは分かっていますが、本当にどんな入力にも問題なく動くのかは、まだあやしいところがあります。
他のCSVパーサとの比較もまだ後にして、次回は全体の動きの見直しと細かい修正を行なっていく予定です。


0 件のコメント:
コメントを投稿