Open PinnedTab LinkというGoogle chromeの機能拡張を作成したので、 Google Chrome Extensionsのデベロッパーガイドを読む必要がありました。
特に Browser Interaction/Tabs (chrome.tabs package)にあるイベントハンドラーの動きがちょっと分かりづらかったので、備忘録的にどういう風に呼ばれるのか図にしてみました。
各ハンドラーの先頭にconsole.log()を入れるローレベルな方法で動きを追ったので、事前条件やテストの方法がまずかったりして違う動きになるかもしれません。
まずは、Graphviz(dot)で図にしてみた
タブを開くたびに上からNormal stateまでのevent handlerメソッド(chrome.tabs.on*())が呼ばれます。
"Normal state"は通常のWebブラウジングをしている状態です。
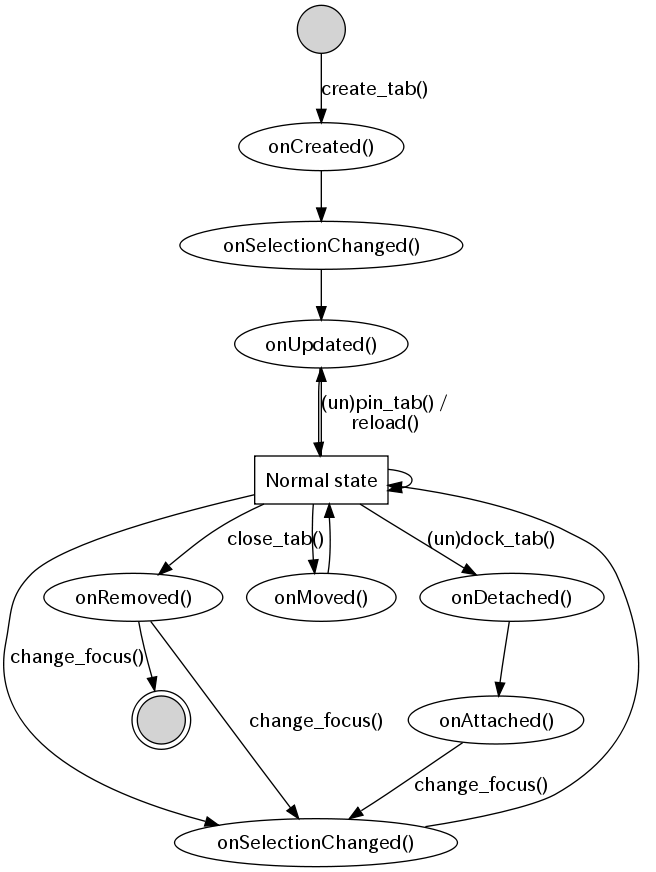
遷移するアクションの説明
説明のない矢印は自動で次の状態に遷移する事を示していて、Chromeのイベントは楕円で示しています。
- create_tab(): Chrome上で新しいタブを開いたり、"Open Link in New Tab"を選択した場合のアクション
- (un)pin_tab(): Pinを固定したり、外したりを選択した場合のアクション
- reloase(): C-rや"Reload"などで明示的にページを更新した場合のアクション
- close_tab(): C-wや"Close Tab"を選択した場合のアクション
- (un)dock_tab(): タブをドラッグして、別ウィンドウに開いたり、別ウィンドウに統合した場合のアクション
- change_focus(): 単純にタブを選択したり、別のタブを閉じたりした事でフォーカスが当った場合のアクション
chrome.tabs.OnRemovedが呼ばれた時には、そのタブは閉じますが、別のタブにフォーカスが当たるので、矢印が2つ出ている事になります。
明示的にTabIDやガード条件のようなものは書いていませんが、適当に読み取れると思います。
楕円で示したところは Events を示していますが、念のため対応する完全修飾のイベント名を列挙しておきます。
- onCreated(): chrome.tabs.onCreated イベント
- onUpdated(): chrome.tabs.onUpdated イベント
- onSelectionChanged(): chrome.tabs.onSelectionChanged イベント
- onDetached(): chrome.tabs.onDetached イベント
- onAttached(): chrome.tabs.onAttached イベント
- onMoved(): chrome.tabs.onMoved イベント
- onRemoved(): chrome.tabs.onRemoved イベント
図を生成する元のdotファイル
図を生成するためのa.dotファイル
// Statechart diagram of chrome.tabs.on*()
digraph G {
start [shape=circle, label="", style=filled];
normal [shape=rect label="Normal state"];
closed [shape=doublecircle, label="", style=filled];
onCreated [label="onCreated()"];
onSelectionChanged [label="onSelectionChanged()"];
onSelectionChanged_ [label="onSelectionChanged()"];
onUpdated [label="onUpdated()"];
onRemoved [label="onRemoved()"];
onMoved [label="onMoved()"];
onDetached [label="onDetached()"];
onAttached [label="onAttached()"];
start -> onCreated [label="create_tab()"];
onCreated -> onSelectionChanged_;
onSelectionChanged_ -> onUpdated;
onUpdated -> normal;
// normal state
normal -> normal;
normal -> onSelectionChanged [label="change_focus()"];
onSelectionChanged -> normal;
// change tab position
normal -> onMoved;
onMoved -> normal;
// pin or unpin tab
normal -> onUpdated [label="(un)pin_tab() /\nreload()"];
// dock or undock tab
normal -> onDetached [label="(un)dock_tab()"];
onDetached -> onAttached;
onAttached -> onSelectionChanged [label="change_focus()"];
// close tab
normal -> onRemoved [label="close_tab()"];
onRemoved -> onSelectionChanged [label="change_focus()"];
onRemoved -> closed;
}
これを図にするには、dotコマンドを使って次のようなコマンドラインを使っています。
$ dot -Tpng -o a.png a.dot
困ったこと
複数のタブを保存して開いた時に、chrome.tabs.onUpdated が呼ばれずに、いきなり chrome.tabs.onSelectionChanged が呼ばれる場合がありました。
さらに悪いことに、この場合には Pin Tab かどうか確実に判別することができませんでした。
そのためタブを保存した状態のChromeを起動して、偶然この問題に遭遇するとPin/Unpinを判別するような機能拡張がうまく動作しない場合があります。
Open PinnedTab Linkでは、この他にもUnpinの場合にContext Menuを無効にするようにしたかったのですが、いまのところ良い手がなく全てのタブの中にメニューを表示しています。
問題はいろいろありますが、タブをブックマーク的に使う初期の目標は達成できたので良しとしましょう。 でも当然ユーザーは不満に思いますよね、「無駄なら消してよ」って。うーん、困ったなぁ。