組み込み用途に特化した軽量版Rubyの実装として、mrubyがリリースされています。
これの使いどころを考えてみたのですが、Tech-Onのインタビュー記事では、一例としてC言語で記述が難しい処理をmrubyにオフロードするとありました。
個人的には静的なコードはC言語で書くだろうと考えていて、動的なランタイムの変更をmrubyでユーザーに開放するんだろうなと思っています。
具体的には設定ファイルの記述やプラグインをmrubyスクリプトで作成することになるでしょう。
この使い方だけならluaなんかでも良いんですが、操作可能な要素をクラス単位でまとめる事ができるのは、実際のところ名前空間があるかどうかの違いぐらいしかありませんが、実用上の使い勝手は表面的な違い以上のものがあると感じています。
まぁ、ここら辺はいまのところ信念の問題なのですが、今回はmrubyを使って設定要素をクラスにまとめる場合を想定して、ちょっとしたサンプルを作ってみる事にしました。
テストした環境とmrubyのバージョンは次のようになっています。
特定のmrubyのバージョンには依存していないと思いますが、Webで調べたコードの中の関数の引数の取り方が違うものもあったので、念のため書いておきます。
- OS: Ubuntu 12.04 LTS x86_64版
- コンパイラ: gcc 4.6.3
- mruby git commit: 8b6f6faf1e3771c04a1e2a58b1bbc84fe7d5c1e2
ちなみに、commit:のハッシュを使って、このテストしたmrubyと同じソースコードをbranch名"20120723.083824"で入手するには次のようにします。
$ git clone https://github.com/mruby/mruby.git
$ git checkout -b 20120723.083824 8b6f6faf1e3771c04a1e2a58b1bbc84fe7d5c1e2
mrubyのバージョンや日付によってメソッドの呼び出しシグネチャが違う事がありますが、だいたいそのまま読めると思います。
参考資料
参考にしたのは、主に手探りでおぼえるmruby その1:クラスを定義する、メソッドを定義するで、RICOHの方がまとめた記事もありましたがコードがGPLだったりするので、考え方などを参考にするに留めています。
とりあえずmrubyについては使い方よりも、生み出された背景や、中間コンパイラとしての挙動について、mrbcコマンドの動きを抑えておくのがお勧めです。
実証実験に参加した各種企業が公開しているドキュメントが参考になるでしょう。
mrubyのサイズ
x86_64環境でライブラリをenv COMPILE_MODE=release makeで作成すると、libmruby.a, libmruby_core.aの各ファイルはそれぞれ790KB前後のサイズになります。(strip後は470KB前後)
ruby-1.9.3-p194のコードをビルドすると、librucy-static.aのサイズはstrip後も2.1MBほどになります。
ライブラリの全てのシンボルとリンクする分けでもないので、静的にリンクした実行ファイルのサイズはもっと小さくなるはずですですが、CRubyのライブラリサイズの大きさは少し大き過ぎるなぁと感じるところです。
mrubyに求める機能
既に説明していますが、アプリケーションが提供するクラスを主体として、そのオブジェクトを組み込みメソッドを組み合せて操作できるところがメリットだろうと思っています。
普通のアプリケーションでは設定ファイルに固定文字列しか書けないのが普通ですが、これはセキュアだとは思うものの、記述できる語彙が少な過ぎるとも感じています。
luaはちょっとローレベルに過ぎる印象があってオブジェクト的に構造体の中に値と操作用関数をまとめる事はできますが、その環境をセットアップするのは少し面倒な印象です。
今回のゴール
mrubyを通してユーザーは日時情報や外部ファイルに記述されている内容などの情報に応じて振舞いを変化させる事ができるようになるといいなぁというわけですが、サンプルなので今回の範囲は一組のsetter/getterをラップしてみようと思います。
具体的に何をするのか、図にしてみた
図にしてみると次のようなプログラムを作成してみる事になります。
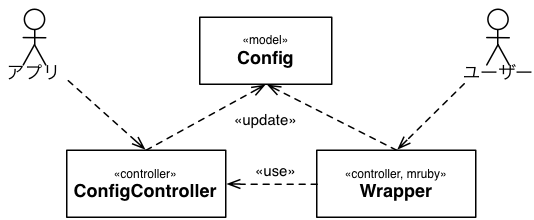
C言語レベルではConfigクラスに相当する設定可能な要素を構造体で定義します。
アプリからは直接構造体を操作せず、操作用のsetter/getterメソッドをConfigControllerクラスとしてまとめています。mrubyからはWrapperクラスを通してConfigControllerファイルでまとめているメソッドにアクセスしています。
実際のコード
いろいろ大風呂敷を広げましたが、ここから先はしょぼいコードが並びます。
ただGoogleで検索にヒットしたページは、やはりmrubyにコードをオフロードする仕組みやmrbcを使って中間コードを実行する方法に特化していたりしたので、もうちょっと泥くさい使い方を考えてみました。
conf.h, conf.c
実際にはConfとConfControllerに相当する機能はconf.c, conf.hにまとめました。
でも何かするわけではなくて、デバッグモードかどうかを動的に切り替えられるというだけです。
内容にはまったく意味がないんですが、気にしないでください。
conf.hファイル
#ifndef YA_CONF_H
#define YA_CONF_H 1
#include <mruby.h>
struct _conf {
int is_debug;
} conf;
int is_debug(void);
void set_is_debug(int d);
#endif
conf.cファイル
#include "conf.h"
int is_debug(void) {
return conf.is_debug;
}
void set_is_debug(int d) {
conf.is_debug = d;
}
wrapper.h, wrapper.c
wrapper.hファイル
#ifndef YA_WRAP_H
#define YA_WRAP_H 1
#include <mruby.h>
struct RClass* yamrb_class;
mrb_state* yamrb_init(void);
mrb_value yamrb_is_debug(mrb_state* mrb, mrb_value self);
mrb_value yamrb_is_debug_equal(mrb_state* mrb, mrb_value self);
#endif
wrapper.cファイル
#include "conf.h"
#include "wrapper.h"
#include <mruby.h>
#include <mruby/numeric.h>
mrb_state* yamrb_init() {
mrb_state* mrb = mrb_open();
yamrb_class = mrb_define_class(mrb, "YaConf", mrb->object_class);
mrb_define_method(mrb, yamrb_class, "is_debug", yamrb_is_debug, ARGS_NONE());
mrb_define_method(mrb, yamrb_class, "is_debug=", yamrb_is_debug_equal, ARGS_REQ(1));
return mrb;
}
mrb_value yamrb_is_debug(mrb_state* mrb, mrb_value self) {
mrb_value ret = mrb_fixnum_value(is_debug());
return ret;
}
mrb_value yamrb_is_debug_equal(mrb_state* mrb, mrb_value self) {
mrb_int arg_debug;
int argc = mrb_get_args(mrb, "i", &arg_debug);
if(argc == 1) {
set_is_debug(arg_debug);
}
return self;
}
main.c
#include <stdio.h>
#include "conf.h"
#include "wrapper.h"
#include <mruby.h>
#include <mruby/proc.h>
#include <mruby/compile.h>
mrb_state *mrb;
int gen_code_num;
mrbc_context *mrbc_ctx;
void init() {
mrb = yamrb_init();
FILE *fp = fopen("main.rb","r");
mrbc_ctx = mrbc_context_new(mrb);
struct mrb_parser_state* st = mrb_parse_file(mrb, fp, mrbc_ctx);
fclose(fp);
gen_code_num = mrb_generate_code(mrb, st->tree);
mrb_pool_close(st->pool);
}
int main(int argc, char** argv) {
init();
// first run
printf("current is_debug: %d\n", is_debug());
mrb_run(mrb, mrb_proc_new(mrb, mrb->irep[gen_code_num]), mrb_nil_value());
printf("current is_debug: %d\n", is_debug());
set_is_debug(1);
printf("new is_debug: %d\n", is_debug());
// second run
mrb_run(mrb, mrb_proc_new(mrb, mrb->irep[gen_code_num]), mrb_nil_value());
// close
mrbc_context_free(mrb, mrbc_ctx);
mrb_close(mrb);
}
main.rb
print "-- begin --\n"
y = YaConf.new()
p y.is_debug()
y.is_debug = 2
p y.is_debug()
print "----\n"
Makefileファイル
INC = ./src/include
LIB = ./src/lib
main: conf.o wrapper.o main.c
gcc -std=gnu99 -I. -I$(INC) -o main main.c conf.o wrapper.o -L$(LIB) -lmruby -lm
conf.o: conf.c conf.h
gcc -std=gnu99 -I. -I$(INC) -c conf.c
wrapper.o: wrapper.c wrapper.h
gcc -std=gnu99 -I. -I$(INC) -c wrapper.c
気になったこと
Rubyの拡張ライブラリの知識は、いろんな意味で役に立ちますが、README.EXT.jaに対応するまとまったドキュメントがないので、いろいろ混乱するかもしれません。
FIX2INTなどの型変換マクロがない
Rubyの拡張ライブラリでは標準的なC言語の型との変換はマクロで実現していましたが、
mruby.hでは静的な関数が準備されています。
- static mrb_value mrb_fixnum_value(mrb_int)
- static mrb_value mrb_float_value(mrb_float)
- などなど
mrb_intは標準のint型とtypedefされているだけで、直接に代入できます。
mrb_floatはmrbconf.hで定義されていますが、手元では8byteで通常はdouble型に紐付くようです。
文字列はmruby/string.hに定義されているような、組み込みString型用の関数を使う事になります。
mruby.hに定義されていなければ、操作対象の型に応じてmruby/以下のヘッダーファイルを眺める事になります。
mrb_generate_code()が返すint型の番号を管理する方法が欲しい
これはmrubyが準備する話しではないのですが、今回は処理が単純なのでmrbも全体で共有するような作りにしました。少し複雑になってきても、必要な都度、必要なコードをmrb_run()で呼びますが、この場合には対象のコードをmrb_generate_code()の戻り値で指定する必要がでてきます。
この管理方法が、まぁ対象のアプリに依りますが、どうなるかなぁと思っているところです。
まとめ
rubyはいろいろ機能が増えすぎて特定のバージョンとコードを密接に管理する必要があるので、mrubyはシンプルに保って欲しいなぁと思っています。まぁコンパイル時のオプションで調整することもできる部分もありますが。
C言語でアプリを組む時に機能の一部をオフロードする目的だと内蔵クラスや機能が多い方が楽になるわけですが、アプリケーションのプラグイン的にユーザーに開放する場合には、むしろ機能や組み込みクラスはないぐらいの方がセキュアになります。
mrubyは現状ミニマムで、これからスタンダード、フルといった主にクラスが追加される形のバージョンが出てくる事になっています。
とはいえ、ミニマムしかない現状でアプリの拡張をmrubyで行なおうとすると物足りない印象はあるので、前倒しでミニマウなmrubyが拡張されるような可能もあるのかなぁと思っています。
クラスセットについては、決まっているようですけれど、環境としてはまだまだ機能の追加が続いていますしね。
どうなるか、まだよくわかりませんが、アプリのコアエンジンとして安定してくれるといいなぁと思います。

