CouchDBを使うためのネタとして 郵便番号検索 (http://www.yadiary.net/postal/)を作成しています
ここで入力をサポートするためにjQueryプラグインのFlexBoxから、候補を検索するためのQueryを投げて、CouchDBから候補となるkeyを取り出しています。
このFlexBoxは必要に応じてリクエストを投げていて、全件数を内部的に持つことはしていません。
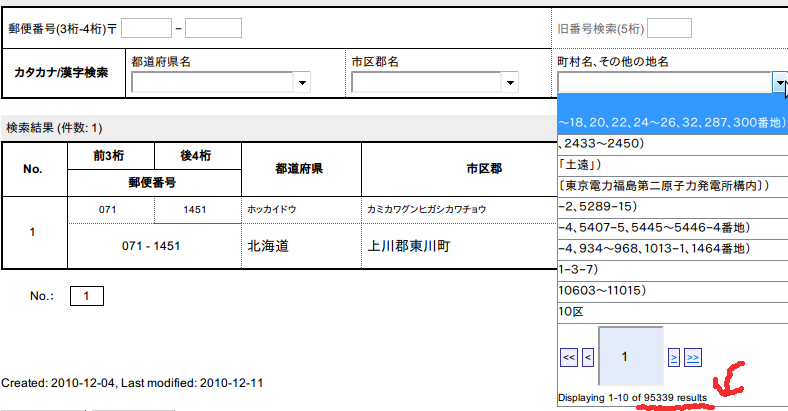
この画像ではFlexBoxに表示されるべき候補が9万5千件あって、その先頭10件が表示されている様子を示しています。 この数字は、各ページの先頭に編集中の文字列が追加されているので、実数からページ数分だけ水増しされています。
この9万5千件という数字は、FlexBoxからの10件毎のQueryへの返信に加える必要があります。
つまり通常のCouchDBで普通に作成すると、毎回の問い合わせの返信内容は10件の内容なのに、全件数を追加するために、内部的にはこの9万5千件のデータを取得して件数の数字だけを作る事になります。
もちろんサーバ側で9万5千という数字をキャッシュする事は可能で、今回も9万5千件という数字もFastCGIの起動時に計算して保持しています。
他の数字についてもキャッシュする事は可能です。 しかし、今回はホスティング環境(DTIのVPS - Entry)でのメモリの制約があります。
RubyスクリプトでHashオブジェクトによる試作では、FastCGI RubyスクリプトのResident Memoryのサイズ上昇が許容範囲を越えていました。
そこでCouchDBだけに負荷を押し付けて、件数を返す機能を追加することにしました。
- 前書きの後の前書き 〜 技術的背景の説明
- まず結論から
- 基本事項の確認 - group=trueな時のCouchDBの内部動作
- 使い方 - 追加したオプションパラメータ
- まとめ
- Appendix. CouchDB 1.0.1用パッチ
前書きの後の前書き 〜 技術的背景の説明
CouchDBに関連するドキュメントでは、いわゆる重複を取り除いた結果を取り出すためのSQLでいうところの SELECT DISTINCT に相当する方法として、VIEWについてmap/reduceの両関数を定義して、 group=trueを引数に加える方法を紹介しています。
この時のreduce関数は組み込みの"_sum"や"_count"にするのが一般的でしょう。
大抵はこれで問題ありませんが、SELECT DISTINCTした結果が、それでも比較的大きかった場合に、その全数を数え上げるための方法が問題になります。
ここでは一度JSONをHashオブジェクト等に変換して、その長さを求めることを考えます。
クライアント例:/examples/_design/allに、View名allを設定している場合に、allの結果を数え上げる
@couth = Couch::Server.new("localhost", "5984")
uri = '/examples/_design/all/_view/all?group=true'
json = JSON.parse(@couch.get(URI.escape(uri)).body)
printf "num of distinct rows: %d\n", json['rows'].lengthnum of distinct rows: 1039
この時にクライアント側のHashオブジェクト(json)は大量のメモリを消費します。 戻り値(@couch.get(...).body)をテキストとしてパースする事もできますが、それでも、ネットワーク帯域とレイテンシの観点からみて、大量のStringオブジェクトを経由する処理は効率的とはいえません。
今回はSQLでいうところの SELECT COUNT(DISTINCT field) FROM tableに相当する処理をCouchDBにさせてみる事を考えました。
まず結論から
今回の方法は軽量プロセスを生成して、Group化された結果(e.x. {"key"=>"三重県", "value"=>2473})を表示する部分で回数だけを軽量プロセスにカウントさせて、最後にその結果だけを受け取って軽量プロセスを終了させる方法をとりました。
タイムアウトやらのエラー処理は十分ではないですし、linkしていないためにプロセスが滞留する可能性もあるかもしれません。
結果はおもしろくなりましたが、かなりad-hocなパッチになっている事はご理解ください。
また軽量プロセスのプログラミングについては、 Erlang Worldを参考にさせて頂き、ほぼその内容に依っています。
基本事項の確認 - group=trueな時のCouchDBの内部動作
CouchDBへViewを設定すると、保持しているドキュメントの一部をキーとしてまとめて表示したり(map関数)、そのまとめたドキュメントの数を数えたり(reduce関数)することができます。
さらにgroup=trueを追加してリクエストを投げると、そのキーの重複を排除して表示することができます。
しかし、この重複を排除したキーの合計数を取り出す仕組みがないために、今回のようにメモリが潤沢でなかったり、reduceしてもまだ結果が大きい場合に問題が起こります。
CouchDBがgroup=true時にやっていること、と解決へのアプローチ
内部での処理は、ほぼ apache-couchdb-1.0.1/src/couchdb/couch_httpd_view.erl で完結しています。
先頭からいくつかの関数の連鎖を通って、send_json_reduce_row(Resp, {Key, Value}, RowFront)関数が出力する文字列(e.x. {"key"=>"三重県", "value"=>2473})を作っています。
send_json_reduce_row関数
send_json_reduce_row(Resp, {Key, Value}, RowFront) ->
send_chunk(Resp, RowFront ++ ?JSON_ENCODE({[{key, Key}, {value, Value}]})),
{ok, ",\r\n"}.本質的にはこの関数を呼び出しているDatabase Engine部分に手を入れ、件数をカウントさせて、関数の戻り値に入れれば良さそうですが、いまのsend_json_reduce_rowの引数をみると、戻り値を受けられるような余地はありません。
内部的には出力を素早く行なうための機能に特化しているようにみえて、今回は、このsend_json_reduce_row関数が呼び出された回数を数えることにしました。
内部的にグローバル変数のようなものを持たせるわけにはいかないので、処理の前半で軽量プロセスを作成して、その後に呼ばれる関数引数を増やしてそのPidを適当な処理まで渡しています。
変数"Pid"に注目すればコードを追うのは簡単だと思います。パッチ本体とファイルへのリンクはこの記事の最後に載せました。
使い方 - 追加したオプションパラメータ
今回はgroup=trueと併用する group_numrowsというパラメータを増やしました。
例えば 郵便番号検索Databaseに入っている都道府県(pref)について、group=trueをした場合の件数(47)を数えると次のようになります。
$ curl -u reader:xxxxxx 'http://localhost:5984/postal/_design/all/_view/pref?group=true&group_numrows=true'
この出力は次の通りです。
{"group_numrows":"47"} group_numrows=falseとした時の出力(の一部)は次の通りです。 "value"の数字は郵便番号DBの全レコード12万件中の何件分かを表していることになります。
{"rows":[
{"key":"\u4e09\u91cd\u770c","value":2473},
{"key":"\u4eac\u90fd\u5e9c","value":6658},
... ## 47都道府県分のデータが続く さらに郵便番号的に、第二フィールドの市区郡(city)の全数はいくつあるのか数えると…
$ curl -u reader:xxxxxx 'http://localhost:5984/postal/_design/all/_view/city?group=true&group_numrows=true'
この出力は次の通りです。
{"group_numrows":"1899"} これが役に立つのはgroup=trueで返される文字列が、その環境では大き過ぎる場合です。
CouchDB内部で節約できている処理は出力用文字列を生成する部分だけですから、何かB-Treeをトリッキーな方法でtraverseしているわけではありません。
この他のアプロートとしては、RDBMSが中間結果を保持する一時テーブルのように、あらかじめオリジナルの文書群から、中間処理用の文書群を生成しておくこともできるはずです。
まとめ
SQLでいうところのSELECT COUNT(DISTINCT field)が使えないのは、CouchDBのskip, limitパラメータの威力を弱めてしまっていると思います。
jQueryプラグインのFlexBoxとCouchDBは組み合せると、かなり大きなデータも扱う事ができそうだという事が実感できました。
次はFlexBoxのcache更新のタイミングが問題でしょうか…。
Appendix. CouchDB 1.0.1用パッチ
- apache-couchdb-1.0.1.group_numrows.20101214.diff(sha1sum: 0ec78c0549ed0c607ac3ef8eb986d76dc61528aa)
diff -ur apache-couchdb-1.0.1.orig/src/couchdb/couch_db.hrl apache-couchdb-1.0.1/src/couchdb/couch_db.hrl
2010
--- apache-couchdb-1.0.1.orig/src/couchdb/couch_db.hrl 2010-07-20 07:59:53.000000000 +0900
+++ apache-couchdb-1.0.1/src/couchdb/couch_db.hrl 2010-12-14 09:54:37.000000000 +0900
@@ -190,6 +190,7 @@
skip = 0,
group_level = 0,
+ group_numrows = false,
view_type = nil,
include_docs = false,
diff -ur apache-couchdb-1.0.1.orig/src/couchdb/couch_httpd_view.erl apache-couchdb-1.0.1/src/couchdb/couch_httpd_view.erl
--- apache-couchdb-1.0.1.orig/src/couchdb/couch_httpd_view.erl 2010-08-08 11:25:40.000000000 +0900
+++ apache-couchdb-1.0.1/src/couchdb/couch_httpd_view.erl 2010-12-14 10:08:16.000000000 +0900
@@ -155,15 +155,22 @@
group_level = GroupLevel
} = QueryArgs,
CurrentEtag = view_group_etag(Group, Db),
+ Pid = case get_group_numrows_type(Req) of
+ true -> spawn(fun() -> group_numrows_server() end);
+ _ -> false
+ end,
couch_httpd:etag_respond(Req, CurrentEtag, fun() ->
{ok, GroupRowsFun, RespFun} = make_reduce_fold_funs(Req, GroupLevel,
QueryArgs, CurrentEtag, Group#group.current_seq,
- #reduce_fold_helper_funs{}),
+ #reduce_fold_helper_funs{}, Pid),
FoldAccInit = {Limit, Skip, undefined, []},
{ok, {_, _, Resp, _}} = couch_view:fold_reduce(View,
RespFun, FoldAccInit, [{key_group_fun, GroupRowsFun} |
make_key_options(QueryArgs)]),
- finish_reduce_fold(Req, Resp)
+ case get_group_numrows_type(Req) of
+ true -> finish_reduce_fold(Req, Resp, [], Pid);
+ _ -> finish_reduce_fold(Req, Resp)
+ end
end);
output_reduce_view(Req, Db, View, Group, QueryArgs, Keys) ->
@@ -173,10 +180,14 @@
group_level = GroupLevel
} = QueryArgs,
CurrentEtag = view_group_etag(Group, Db, Keys),
+ Pid = case get_group_numrows_type(Req) of
+ true -> spawn(fun() -> group_numrows_server() end);
+ _ -> false
+ end,
couch_httpd:etag_respond(Req, CurrentEtag, fun() ->
{ok, GroupRowsFun, RespFun} = make_reduce_fold_funs(Req, GroupLevel,
QueryArgs, CurrentEtag, Group#group.current_seq,
- #reduce_fold_helper_funs{}),
+ #reduce_fold_helper_funs{}, Pid),
{Resp, _RedAcc3} = lists:foldl(
fun(Key, {Resp, RedAcc}) ->
% run the reduce once for each key in keys, with limit etc
@@ -190,7 +201,10 @@
{Resp2, RedAcc2}
end,
{undefined, []}, Keys), % Start with no comma
- finish_reduce_fold(Req, Resp, [{update_seq,Group#group.current_seq}])
+ case get_group_numrows_type(Req) of
+ true -> finish_reduce_fold(Req, Resp, [{update_seq,Group#group.current_seq}], Pid);
+ _ -> finish_reduce_fold(Req, Resp, [{update_seq,Group#group.current_seq}])
+ end
end).
reverse_key_default(?MIN_STR) -> ?MAX_STR;
@@ -203,6 +217,9 @@
get_reduce_type(Req) ->
list_to_existing_atom(couch_httpd:qs_value(Req, "reduce", "true")).
+get_group_numrows_type(Req) ->
+ list_to_existing_atom(couch_httpd:qs_value(Req, "group_numrows", "false")).
+
load_view(Req, Db, {ViewDesignId, ViewName}, Keys) ->
Stale = get_stale_type(Req),
Reduce = get_reduce_type(Req),
@@ -303,6 +320,8 @@
[{reduce, parse_bool_param(Value)}];
parse_view_param("include_docs", Value) ->
[{include_docs, parse_bool_param(Value)}];
+parse_view_param("group_numrows", Value) ->
+ [{group_numrows, parse_bool_param(Value)}];
parse_view_param("list", Value) ->
[{list, ?l2b(Value)}];
parse_view_param("callback", _) ->
@@ -385,6 +404,8 @@
% Use the view_query_args record's default value
validate_view_query(include_docs, _Value, Args) ->
Args;
+validate_view_query(group_numrows, _Value, Args) ->
+ Args;
validate_view_query(extra, _Value, Args) ->
Args.
@@ -393,7 +414,7 @@
start_response = StartRespFun,
send_row = SendRowFun,
reduce_count = ReduceCountFun
- } = apply_default_helper_funs(HelperFuns),
+ } = apply_default_helper_funs(HelperFuns, Req, Req),
#view_query_args{
include_docs = IncludeDocs
@@ -425,10 +446,13 @@
end.
make_reduce_fold_funs(Req, GroupLevel, _QueryArgs, Etag, UpdateSeq, HelperFuns) ->
+ make_reduce_fold_funs(Req, GroupLevel, _QueryArgs, Etag, UpdateSeq, HelperFuns, nil).
+
+make_reduce_fold_funs(Req, GroupLevel, _QueryArgs, Etag, UpdateSeq, HelperFuns, Pid) ->
#reduce_fold_helper_funs{
start_response = StartRespFun,
send_row = SendRowFun
- } = apply_default_helper_funs(HelperFuns),
+ } = apply_default_helper_funs(HelperFuns, Req, Pid),
GroupRowsFun =
fun({_Key1,_}, {_Key2,_}) when GroupLevel == 0 ->
@@ -488,7 +512,7 @@
#view_fold_helper_funs{
start_response = StartResp,
send_row = SendRow
- }=Helpers) ->
+ }=Helpers, _Req, _Pid) ->
StartResp2 = case StartResp of
undefined -> fun json_view_start_resp/6;
_ -> StartResp
@@ -504,19 +528,21 @@
send_row = SendRow2
};
-
apply_default_helper_funs(
#reduce_fold_helper_funs{
start_response = StartResp,
send_row = SendRow
- }=Helpers) ->
+ }=Helpers, Req, Pid) ->
StartResp2 = case StartResp of
undefined -> fun json_reduce_start_resp/4;
_ -> StartResp
end,
SendRow2 = case SendRow of
- undefined -> fun send_json_reduce_row/3;
+ undefined -> case get_group_numrows_type(Req) of
+ true -> gen_send_json_reduce_row(Pid);
+ _ -> fun send_json_reduce_row/3
+ end;
_ -> SendRow
end,
@@ -586,6 +612,24 @@
send_chunk(Resp, RowFront ++ ?JSON_ENCODE({[{key, Key}, {value, Value}]})),
{ok, ",\r\n"}.
+gen_send_json_reduce_row(Pid) ->
+ fun(_Req, _KV, _RowFront) ->
+ Pid ! {countup},
+ {ok, ",\r\n"}
+ end.
+
+group_numrows_server() ->
+ group_numrows_server(0).
+group_numrows_server(X) ->
+ receive
+ {status, From} ->
+ From ! X, group_numrows_server(X);
+ {countup} ->
+ group_numrows_server(X+1);
+ {stop, From} ->
+ From ! X
+ end.
+
view_group_etag(Group, Db) ->
view_group_etag(Group, Db, nil).
@@ -651,6 +695,25 @@
finish_reduce_fold(Req, Resp) ->
finish_reduce_fold(Req, Resp, []).
+get_group_numrows_final_results(Pid) ->
+ Pid ! {stop, self()},
+ receive
+ X -> X
+ end.
+
+finish_reduce_fold(Req, Resp, Fields, Pid) ->
+ case Resp of
+ undefined ->
+ send_json(Req, 200, {[
+ {rows, []},
+ {group_numrows, 0}
+ ] ++ Fields});
+ Resp ->
+ X = get_group_numrows_final_results(Pid),
+ send_chunk(Resp, "{\"group_numrows\":\"" ++ integer_to_list(X) ++ "\"}"),
+ end_json_response(Resp)
+ end.
+
finish_reduce_fold(Req, Resp, Fields) ->
case Resp of
undefined ->

0 件のコメント:
コメントを投稿