いくつかのプログラミング言語を使って同じCSVファイルを処理してみました。 気がついたところから簡単なパフォーマンスチューニングも行なってみました。
今回実行時間を表示していますが、環境はAMD Phenom II 940BE (2.6GHz)、 Ubuntu 10.04 LTS 64bitです。
現状の課題
サンプルプログラム程度でrubyやpythonと比較しようと思います。 手元にはJUnitでのテストケースで作成した、重複はしていますが、1行に1フィールドで完結している16k x 2個ほどのファイルがあります。
このファイルを適当に組み合せて1ファイル/1行に0〜3フィールド程度を複数行持つ、単一の数100kBのCSVファイルを準備してみます。
簡単に図にすると次のようなイメージです。
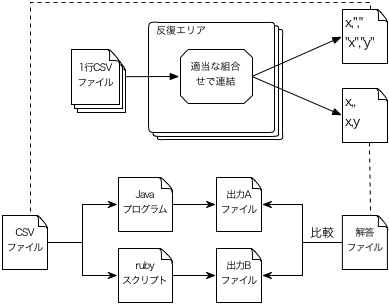
こういう時の作業は、それこそpythonやrubyが簡単です。
およそ次のようなコマンドラインで実行する事を考えました。
$ time java CSVScanner.jar < input.csv > output.txt $ time ruby scanner.rb < input.csv > output.txt $ ... etc.
Pythonスクリプト
#!/usr/bin/python
import csv
import sys
reader = csv.reader(sys.stdin)
for row in reader:
for field in row:
sys.stdout.write(field)
sys.stdout.write('\n')Ruby 1.9スクリプト
#!/usr/bin/ruby1.9
require 'csv'
CSV.parse(STDIN) do |row|
row.each do |i|
print i
end
print "\n"
endJavaCSV2.0対応版
import com.csvreader.CsvReader;
public class Main {
public static void main(String[] args) {
CsvReader reader = null;
try {
reader = new CsvReader(System.in, ',', java.nio.charset.Charset.forName("UTF-8"));
while(reader.readRecord()) {
String[] values = reader.getValues();
for(String item : values) {
System.out.print(item);
}
System.out.println("");
}
} catch(java.io.IOException e) {
e.printStackTrace();
}
if (reader != null) {
reader.close();
}
}
}プログラムは各ライブラリのサンプルと同じ程度の内容で、同じ出力を得るようにサンプルコードを参考にシンプルに作成したつもりです。 timeコマンドでUser時間を計測したところ、次のような結果になりました。
![インタプリタ別の実行時間[秒]]( http://www.yasundial.org/blog/images/20101101.1.csvparsers.jpg)
この数字はインタプリタの起動を含めた処理から終了までの一連のCPUを占有した経過時間になっています。
Javaはインタプリタの起動に時間がかかるのか、というと、たしかに軽くはないけど、そういうわけでもなさそうです。
csvreader.comが開発しているJavaCSV2.0を使った結果はRuby 1.8とRuby 1.9の間に収まっています。
作成したCSVパーサで問題になりそうなところを考えていきます。
パフォーマンスチューニング
根本的にはjava.util.Scannerを使っている点と、正規表現に頼っている点が速度低下に大きく関係しているはずです。 改善するとすれば、次のようなところでしょうか。
- 正規表現を使うメソッドの利用を抑制
- フィールド前後のダブルクォートを取り外す処理を変更
- Scannerオブジェクトによる"\n"の分割を変更
- java.io.BufferedReader::readLine()利用
- java.io.BufferedReader::read()を使って手動で実装
- Scannerオブジェクトによる","の分割を変更
- line.split(",")を利用
- java.io.BufferedReader::read()の利用
問題はどれくらいパフォーマンスの改善に貢献するかというところです。
おそらく正規表現もScannerも使わなければ、JavaCSV2.0ぐらいのスピードになる気はします。 もっともそこまでの変更は今回の出発点からはずいぶんと外れてしまいます。
それにJavaCSV 2.0と同じ事をやってもしょうがないので、確認のためにいくつか変更を加えてtimeコマンドでUser時間を計測してみることにしました。
フィールド前後のダブルクォートを取り外す処理を変更
CSVのルールとして、改行やダブルクォートを含むフィールドでは、エスケープのために前後をダブルクォートで囲む事にしています。
そのため出力する前に "x""y"" を x"y に変更する処理が必要になります。
この処理にString::replaceAll()メソッドを使っていますが、正規表現を使う処理なのと文字列全体を観るために重そうです。
フィールド毎にreplaceAllの呼び出しを3回重ねていたので、2回に修正しました。 たったこれだけですが、1割程度は速度が向上しています。
変更前のreplaceAllメソッド呼び出し
public void add(String field) {
itemList.push(field.replaceAll("^" + this.quoteString, "").replaceAll(this.quoteString + "$", "").replaceAll(this.quoteString + this.quoteString, this.quoteString));
}
変更後のreplaceAllメソッド呼び出し
public void add(String field) {
itemList.push(field.replaceAll("^\"|\"$", "").replaceAll("\"\"", "\""));
}
Scannerオブジェクトによる","の分割を変更
行を読み込む度にScannerオブジェクトを生成して、","で分割するのはコストが高そうな処理です。
これを String::split() を使うように修正したところ速度は2割ちょっと向上しました。
Scannerオブジェクトによる"\n"の分割を変更
この処理用のScannerオブジェクトはファイル全体を指定するので、最初の一回しか作成されません。
この処理を BufferedReader::readLine() を使うようにしてみたり、本格的な処理を考えて BufferedReader::read() を使った処理にしてみても、たいして速度には影響しませんでした。
予想通りでしたが、結果をまとめるとグラフのようになります。
結果をまとめてグラフにしてみる
正規表現は引き続き使っていますが、上記の修正を個別に修正した場合の速度と、それらを組み合せた場合の速度をグラフにしてみました。
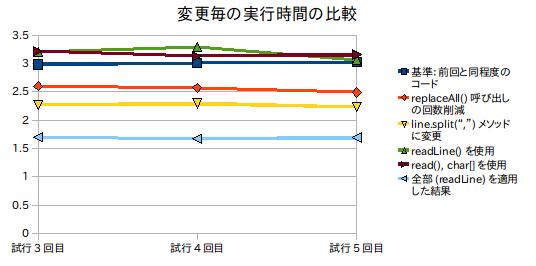
オブジェクトの生成回数が問題かというと、必ずしもそうはいえません。 内部でCSVRowオブジェクトを毎回生成にしていたのですが、それを修正しても速度の向上は数パーセント程度で、誤差の範囲に思われました。
どちらかというと、String::replaceAll()メソッドの呼び出しを一回抑えるだけで効果的だった事に注目するべきでしょう。
正規表現のコンパイルをメソッド呼び出し毎にするとどうなるか
早い段階で修正していましたが、初期のコードではフィールドを区切るための正規表現をgenRow()メソッドの中で毎回初期化していました。
もしこの修正を行なわなかったらどうなったのか、前述のコードに適用すると次のような処理速度になります。
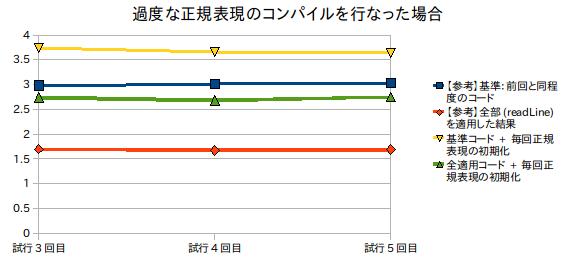
やはり正規表現周りはパフォーマンスの改善には大きく影響しそうです。 まぁ昔からいわれていたことではありますけれど。
さいごに
もしコード全体を最適化するなら、現在の構造自体が問題で、一文字づつ読んで状態を遷移させていく処理に変更することが必要なはずです。
正規表現が関連する処理は、速度に影響することがわかります。 その反面、正規表現を使う事で開発の効率やコードの見た目はとても良くなることは間違いないでしょう。
このバランスを取るためには、特に今回のような単純な例では、よくテストされた構文解析器のジェネレータが強力な武器になると思います。
それはそれで文字種の指定ができなかったりして、Shift_JISは当然として、UTF-8にも対応していない場合があるので注意が必要なんですけどね。



0 件のコメント:
コメントを投稿