AndroidのIn-app Billingは、無料アプリケーションの中で課金アイテムを販売するための仕組みです。
Application Licensingが有料アプリケーションのみを対象としているのと対照的です。
無料と有料とを別々に販売する方法は、アプリ内広告のためのライブラリを省くなどなど、アプリケーションサイズを小さくすることなどはできますが、その反面、コードのメンテナンスやテストはいろいろと面倒だったりします。
無料アプリをそのままにして、有料アプリを頻繁にバージョンアップさせる方法もありますが、
あまり良いインタフェースではなさそうに思えたので、今回は単一のアプリケーションイメージを無料で配布して、
その中で一部機能のロックを解除するツールを販売する方法にしてみました。
このIn-app Billingのサンプルアプリケーションを動かすのも、Androidプログラミング自体が始めての場合には
いろいろと面倒そうですが、手順はいろいろ出回っていて、そもそもDev Guideの手順が一番充実していたりするので、
今回はこのサンプルのコードを自分のアプリケーションに組み込んだ時のログを残す事にしました。
Dungeonsアプリについて
Android Dev. Guideに従って作業を進めると、Google PlayにAPKファイルをアップロードするところまでは簡単に進むと思います。
アップロードしてからすぐに課金アイテムの作成などを行なう事ができるようになりますが、
アプリケーションから正しく処理ができるようになるまでは30分ほどかかりました。
うまく動かない場合には、アイテムを増やしたりするよりも、しばらく時間を置くのが良さそうです。
非署名アプリからの購入テスト
一度署名アプリをGoogle Playに登録して、課金アイテムを登録すると、emacsからアプリを起動した時のように署名をしていないapkから起動したアプリも正常に動き、"android.test.purchased"の購入などのテストができるようになります。
作業の進め方 (方針)
Dungeonsアプリを下敷に、自分のアプリケーションからアイテムの購入ができるようにする方法を考えます。
今回はDungeonsをライブラリに変更せずに、自作アプリケーション配下のパッケージに導入します。
ManagedアイテムとUnManagedアイテム
一回購入すると購入者情報と紐付いて、アプリケーションをアンインストールしようが購入履歴がGoogleに保存されて、再インストールしたアプリにも引き継がれる、それがManagedアイテムです。
よくよくアプリ課金で問題になるコインや武器といった繰り返し購入可能なアイテムはUnmanagedと呼ばれていますが、今回は対象としては考えません。
課金(Billing)機能の組み込みについて
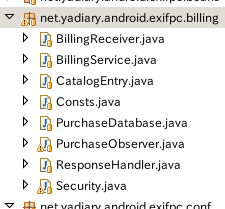
基本的にはDungeonsアプリのDungeons.javaファイルを除いて、全てのファイルを自分のアプリケーションにコピーします。
Eclipse上のPackage Explorerでは次の画像のように、自分のアプリケーションのパッケージの中にbillingサブパッケージを追加して全てのクラスをコピーしてきました。

この他にsrcフォルダに "com.android.vending.billing" パッケージを作成し、IMarketBillingService.aidl ファイルをコピーしておきます。
また"com.example.dungeons.util"パッケージのBase64.javaとBase64DecoderException.javaもコピーしてきます。
参照関係はEclipseのエラーを確認しながら修正していきます。
Dungeonsアプリとの差分について
参照関係を解決しても、Dungeonsアプリ固有のUIを操作している部分は削除する事になります。
パッケージ名やコメント内の重要ではない部分を省いた差分は、概ね次のようになります。
BillingService.java
- class RequestPurchase extends BillingRequest {
+ public class RequestPurchase extends BillingRequest {
- class RestoreTransactions extends BillingRequest {
+ public class RestoreTransactions extends BillingRequest {
Security.javaの差分 (セキュリティ上の理由から省略)
- String base64EncodedPublicKey = "...";
+ String base64EncodedPublicKey = "...";
RequestPurchaseをpublicに変更したのはパッケージnet.yadiary.android.exifpc.billingの外部からアクセスする必要があるからです。
Dungeonsでは単一のパッケージの中に含まれるので意識しない部分ですが、それを除いてもかなり使い周せるように考えられて作られていると思います。
自分のアプリからbillingパッケージにコピーしたクラスを使う
いよいよメインの作業に入っていきますが、Dungeons.javaを参考にしていきます。
購入アイテムのリストを作成する
クラス変数としてCATALOGのエントリを作成します。
今回のアプリでは画面に表示する名称は別途管理するので、このCatalogEntryの第二引数は実際には使っていません。
mBillingServiceインスタンスは外部から操作する必要があるのでアクセスできるよう、getterのみ定義しています。
MainActivityのライセンス関連変数
/*
* ライセンス用設定
*/
private static final String TAG = "ExifPM";
private static final String DB_INITIALIZED = "db_initialized";
private Handler mHandler;
private BillingService mBillingService;
public BillingService getBillingService() {
return mBillingService;
}
private ExifPMPurchaseObserver mExifPMPurchaseObserver;
/**
* カタログ情報はここにまとめ、各Fragmentが参照する
*/
public static final CatalogEntry[] CATALOG = new CatalogEntry[] {
// primary selling tools
new CatalogEntry("exifpm_purchases_item", R.string.billing_item_hiddenads, CatalogEntry.Managed.MANAGED),
// debug items
new CatalogEntry("android.test.purchased", R.string.billing_item_hiddenads, CatalogEntry.Managed.MANAGED),
new CatalogEntry("android.test.canceled", R.string.billing_item_hiddenads, CatalogEntry.Managed.MANAGED),
new CatalogEntry("android.test.refunded", R.string.billing_item_hiddenads, CatalogEntry.Managed.MANAGED),
// please add other stuffs under this line.
};
private PurchaseDatabase mPurchaseDatabase;
onCreateメソッドでのライセンス関連設定
onCreateメソッドでのライセンス関連設定
mHandler = new Handler();
mExifPMPurchaseObserver = new ExifPMPurchaseObserver(mHandler);
mBillingService = new BillingService();
mBillingService.setContext(this);
ResponseHandler.register(mExifPMPurchaseObserver);
if (mBillingService.checkBillingSupported(null) == false) {
// 必要に応じてエラーメッセージを表示する
Toast.makeText(this, R.string.billing_toast_notsupported, Toast.LENGTH_LONG).show();
}
最後のToast文は課金がサポートされていない事を通知するためのメッセージです。
Emulatorなどで実行すると、ここでメッセージが表示されるはずです。
onDestroyでの後始末
課金サービスに限らずServiceに定義したインスタンスはunbindしないと、バックグラウンドで稼働してバッテリーを消費します。
定義されているだけではServiceは起動しませんが、BillingServiceのようにアクセスされ、起動したServiceは、いわゆるlong-runningプロセスとしてシステムが管理します。
GCが動くとか妄想は止めて、必ず停止するようにしましょう。
onDestroyメソッド全体
@Override
protected void onDestroy() {
mBillingService.unbind();
super.onDestroy();
}
PurchaseObserverサブクラスの作成
Activityクラス内にPurchaseObserverのサブクラスを定義します。
ここでは変数として宣言されていた、mExifPMPurchaseObserverを作成していきます。
参考までに作成されたExifPMPurchaseObserver全体は次のようになっています。
ExifPMPurchaseObserverクラス全体 (一部省略)
private class ExifPMPurchaseObserver extends PurchaseObserver {
public ExifPMPurchaseObserver(Handler handler) {
super(MainFragmentActivity.this, handler);
}
@Override
public void onBillingSupported(boolean supported, String type) {
if (type == null || type.equals(Consts.ITEM_TYPE_INAPP)) {
if (supported) {
restoreDatabase();
}
} else if (type.equals(Consts.ITEM_TYPE_SUBSCRIPTION)) {
// This type is not essential of this application
} else {
// not supported state, do nohing.
}
}
/**
* キャンセル、リファンド通知はこのメソッドのpurchaseStateで判断する
*/
@Override
public void onPurchaseStateChange(PurchaseState purchaseState, String itemId, int quantity, long purchaseTime, String developerPayload) {
if (purchaseState == PurchaseState.PURCHASED) {
if (itemId.equals(CATALOG[0].sku) || itemId.equals(CATALOG[1].sku)) {
if (adView != null) {
adView.setVisibility(View.GONE);
}
}
} else if (purchaseState == PurchaseState.CANCELED) {
// do nothing
} else {
// refunded state
if (itemId.equals(CATALOG[0].sku) || itemId.equals(CATALOG[2].sku) || itemId.equals(CATALOG[3].sku)) {
AppConfig.isFreeEdition = false;
}
}
}
@Override
public void onRequestPurchaseResponse(RequestPurchase request, ResponseCode responseCode) {
if (responseCode == ResponseCode.RESULT_OK) {
if (Consts.DEBUG) {
Log.i(TAG, "purchase was successfully sent to server");
}
} else if (responseCode == ResponseCode.RESULT_USER_CANCELED) {
if (Consts.DEBUG) {
Log.i(TAG, "user canceled purchase");
}
} else {
if (Consts.DEBUG) {
Log.i(TAG, "purchase failed");
}
}
}
@Override
public void onRestoreTransactionsResponse(RestoreTransactions request, ResponseCode responseCode) {
AppConfig.sendMessage("called with ResponseCode=" + responseCode);
if (responseCode == ResponseCode.RESULT_OK) {
if (Consts.DEBUG) {
Log.d(TAG, "completed RestoreTransactions request");
}
// Update the shared preferences so that we don't perform
// a RestoreTransactions again.
SharedPreferences prefs = getPreferences(Context.MODE_PRIVATE);
SharedPreferences.Editor edit = prefs.edit();
edit.putBoolean(DB_INITIALIZED, true);
edit.commit();
} else {
if (Consts.DEBUG) {
Log.d(TAG, "RestoreTransactions error: " + responseCode);
}
}
}
}
ここではコンストラクタを除くと4つのメソッドが定義されています。
全てのメソッドの基本的な構造はDungeonsクラスから、そのまま引き継いでいます。
前半のonBillingSupportedとonPurchaseStateChangeは
後半のonRequestPurchaseResponseとonRestoreTransactionsResponseはアプリケーションの動きに応じて、例えばリセットされたアプリケーション起動時にステータスを回復したタイミングで「購入情報を更新中です」みたいなメッセージを表示する事ができます。
restoreDatabaseの動き
バッサリ省略したrestoreDatabaseメソッドは、キャッシュクリアされたアプリを起動した場合などに、購入済み情報を取得するためのメソッドです。
実際の取得処理はmBillingServiceのrestoreTransactionメソッドを呼び出します。
実際の購入処理
このActivityの管理下にあるFragmentから実際の購入処理を呼び出す事になります。
ボタンなどをクリックした時にActivityのBillingServiceインスタンスに対して、
requestPurchaseメッセージを送信します。
この処理は簡単なので省略します。
まとめ
課金処理を追加する事自体でアプリケーションコードは、ほとんど増えませんし、パーミッションも明示的なcom.android.vending.BILLING 1つだけなので、良いソリューションだと思います。
反面、課金処理は簡単ですが、ゲームなんかでコインを購入させるのは、どうかなぁと思います。
単純に時間短縮のためにコインを購入オプションがあって、時間さえかければ先に進めるようなものは良いのですが、ゲームバランスが極端に悪いものは遊んでいてあまりおもしろいとは思いません。
じゃぁなんで課金機能を追加したのかと言われれば、日本の法律では寄付の受付は禁止ですから、アプリケーションを気に入ってもらったり、このブログが参考になったりした場合に、代りにアイテムを購入して頂ければ幸いです。