今回は細かく処理内容を検証して処理構造そのものと、コード全体の見直しについてです。
入力文字列の処理機構
今回のパーサは次のような ENBFルールを満足するはずです。
line = word , { "," , word } ;
word = raw string | quoted string ;
raw string = { "x" } ;
quoted string = """, { "x" | """" | "," } , """;
- Note #1: ダブルクォートを2つ連結した文字は""","""と書かずに""""とする
- Note #2: "x"は空文字列"", カンマ","、ダブルクォート"""を含まない1文字とする
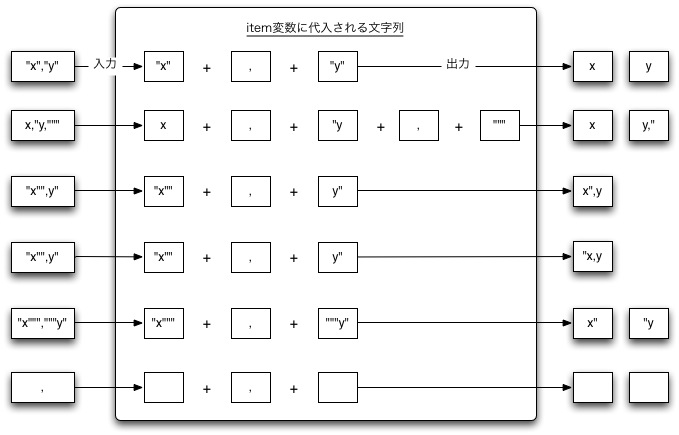
言葉で書いても判りづらいところがあるので、図にすると次のような感じです。
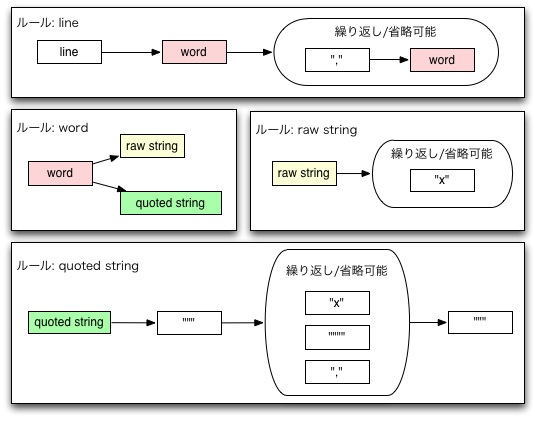
このルールでは空行はraw stringの繰り返し版という事になっています。 このため次のような各行がCSVとして認識することになります。
x x,"x,""" ,
raw stringとquoted stringの認識について
今回は自分の決めたルールでカンマで区切って処理をするため、 word 単位で処理をすることができません。
そのため word 部分を切り出すために、次のようなルールで input を断片化し word を再構成しています。
- ","でlineを raw string と quoted stringの断片 に分割する
- 次のルールでraw stringを認識する
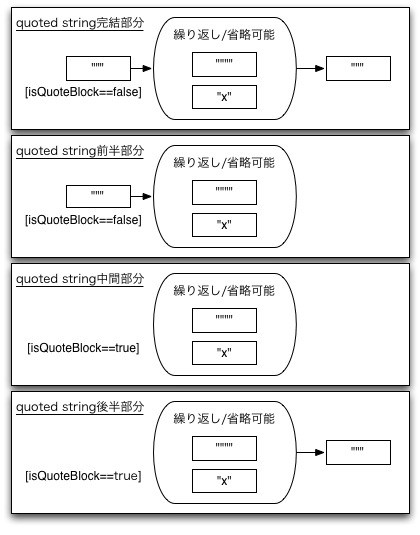
- 条件0 isQuoteBlock==false かつ { "x" } ; で構成されている文字列
- 次のルールでraw stringではないquoted stringの断片を認識します。
- 条件1 完結したquoted string: isQuoteBlock==false かつ """, { """" | "x" } , """ ;
- 条件2 quoted stringの開始要素: isQuoteBlock==false かつ """, { "x" | """" } ; isQuoteBlock = true.
- 条件3 quoted stringの中間要素: isQuoteBlock==true かつ { "x" | """" } ;
- 条件4 quoted stringの終了要素: isQuoteBlock==true かつ { "x" | """" }, """ ; isQuoteBlock = false.
- 条件1であれば、そのままquoted stringと認識
- 条件2であれば、続く条件3の要素を","を加えて連結して、最後に条件4を","を加えて連結してquoted stringと認識
面倒なquoted stringのところだけ図にすると次のようになります。
処理の構造ははっきりしたので、次に前回までで作成したコードの内容と少し比較してみることにします。
作成したコードの見直し
前回までで作成したCSVManagerクラスの動きをgraphvizで図にすると次のようになります。
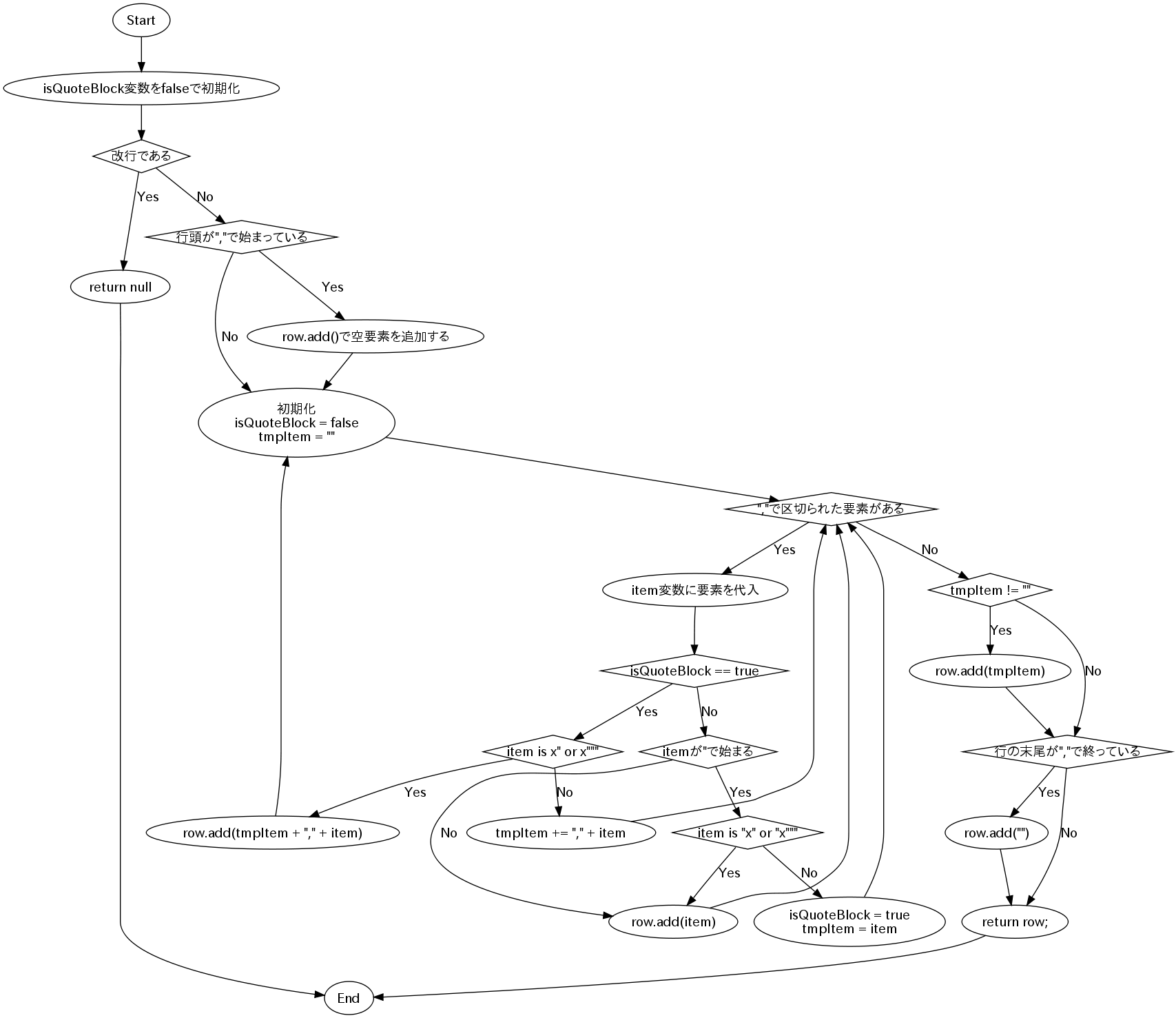
さすがにこれは図にしても、まったく理解できそうにありません。
quoted stringの説明とリンクして要約すると次のような差がある事になります。
- 条件1 """, { """" | "x" } , """ ; の判断は2つの条件に分割して処理している
- isQuoteBlock==false かつ、先頭にダブルクォートを含み、
- 先頭から最後まで偶数個のダブルクォートが連続する
- または、先頭にダブルクォートを含み、途中"x"に相当する文字から最後まで奇数個のダブルクォートが連続する
- isQuoteBlock==false かつ、先頭にダブルクォートを含み、
- 条件2 は isQuoteBlock==false かつ 先頭にダブルクォートを含み、条件1に該当しない場合
- 条件3 は isQuoteBlock==true かつ 条件4に該当しない場合
- 条件4 { "x" | """" }, """ ; の判断は2つに分割している
- isQuoteBlock==true かつ、末尾にダブルクォートを含み、
- 先頭から末尾まで奇数個のダブルクォートが連続する
- または、任意の文字で始まり途中"x"に相当する文字から末尾まで奇数個のダブルクォートが連続する
- isQuoteBlock==true かつ、末尾にダブルクォートを含み、
どっちもどっちですが、ユニットテストを通すようにコードを修正したにしては、ちゃんと同じような動きをするコードになっています。
ところどころ、「先頭にダブルクォートを含み」、「末尾にダブルクォートを含み」のように、それをチェックしなくても続く条件に含まれているような冗長な判断はありますが、ちゃんとしているようです。
ただし、終了条件の中でlineがカンマである場合には無条件に空要素を加えなければいけないのに、tmpItemに要素が残っていない場合だけ判断されるようになっています。
問題のありそうなコード抜粋
if (!tmpItem.isEmpty()) {
row.add(tmpItem);
System.out.println("isQuoteBlock:" + isQuoteBlock);
} else if (line.endsWith(this.itemDelimiter)) {
row.add("");
}tmpItemに何か値が入ったままになるような条件があれば、場合によっては空要素が正しく判断できないことになります。
しかし実際には、最初のEBNFルールを満足する場合、あいまいさはなく、この処理は不要です。 そのため最後でtmpItem変数に値が入っているような状況自体がエラーになります。
付け加えると、最後にisQuoteBlock変数がtrueであるような状況ももちろんエラーです。
何よりも、どのステップを処理しているのか分かりづらいのが致命的です。 ここら辺を修正しつつ、EBNFで記述した文法に対応するようなコードに修正していきます。
正規表現の見直し
それぞれの条件式をみると、同じEBNFルール({ "x" | """" })が確認できます。
この部分を正規表現にすると "^(\"\"|[^\"])*" となるので、この前後に"\""を加えるかどうかと、isQuoteBlock変数の条件を合わせるだけで、分割されたquoted stringの断片を区別する事が可能になります。
raw stringの正規表現はもっと短かく、 "^[^\"]*$" となります。
これを踏まえてCSVManagerクラスのgenRow(String line)メソッドを修正すると、次のようになりました。
変更を加えたコード
正規表現は効率を考えてインスタンス変数として準備してみました。
CSVManagerクラスのコンストラクタに追加したコード部分
+ c0Pattern = java.util.regex.Pattern.compile(String.format("^(%s%s|[^%s])*",
+ quoteString,quoteString,quoteString));
+ c1Pattern = java.util.regex.Pattern.compile(String.format("^%s(%s%s|[^%s])*%s",
+ quoteString,quoteString,quoteString,quoteString,quoteString));
+ c2Pattern = java.util.regex.Pattern.compile(String.format("^%s(%s%s|[^%s])*",
+ quoteString,quoteString,quoteString,quoteString));
+ c3Pattern = java.util.regex.Pattern.compile(String.format("^(%s%s|[^%s])*",
+ quoteString,quoteString,quoteString));
+ c4Pattern = java.util.regex.Pattern.compile(String.format("^(%s%s|[^%s])*%s",
+ quoteString,quoteString,quoteString,quoteString));修正したCSVManager::genRow(String line)メソッド抜粋
private Row genRow(String line) {
if (line.isEmpty()) {
return null;
}
// as example, line is "a,c,b".
java.util.Scanner cScanner = new java.util.Scanner(line);
cScanner.useDelimiter(this.itemDelimiter);
CSVRow row = new CSVRow();
if (line.startsWith(this.itemDelimiter)) {
row.add("");
}
this.isQuoteBlock = false;
String tmpItem = "";
while (cScanner.hasNext()) {
String item = cScanner.next(); // item is one of; "a c b"
if (this.isQuoteBlock) {
if (this.c4Pattern.matcher(item).matches()) {
// Condition#4
tmpItem += this.itemDelimiter + item;
row.add(tmpItem);
this.isQuoteBlock = false;
tmpItem = "";
} else if (this.c3Pattern.matcher(item).matches()) {
// Condition#3
tmpItem += this.itemDelimiter + item;
} else {
// error condition
System.err.println("error condition#1");
}
} else {
if (this.c1Pattern.matcher(item).matches() || this.rsPattern.matcher(item).matches()) {
// Condition#0 or #1
row.add(item);
} else if (this.c2Pattern.matcher(item).matches()) {
// Condition#2
this.isQuoteBlock = true;
tmpItem = item;
} else {
// error condition
System.err.println("error condition#2");
}
}
}
// To salvage the item in progress which is placed at EOF.
if (!tmpItem.isEmpty()) {
// error condition
System.err.println("error condition#3");
}
if (line.endsWith(this.itemDelimiter)) {
row.add("");
}
return (Row) row;
}
エラーは通常行末までいかないと確実には分かりませんが、とりあえず異常な状態かどうかは、はっきりさせることができました。
とりあえず行ベースのCSVパーサについては、ここまでにして改行を含む、本格的なCSVパーサを作っていきます。